Chalk up one more loss for physicists searching for dark matter. Scientists with the XENON100 experiment have largely ruled out another experiment’s controversial claim of detecting dark matter.
XENON100, located in Italy’s Gran Sasso National Laboratory, aims to directly detect particles of dark matter — the unknown substance that scientists believe makes up the bulk of matter in the cosmos (SN: 11/12/16, p. 14).
In their new analysis, published online January 3 at arXiv.org, XENON100 scientists looked for an annual variation in the rate of blips in their detector, a tank filled with 161 kilograms of liquid xenon. Such a signal could be a hallmark of Earth’s motion through a prevailing wind of dark matter particles as the planet makes its yearly jaunt around the sun. Another dark matter experiment at Gran Sasso, DAMA/LIBRA, claims to have found strong evidence of a yearly modulation, but other experiments have failed to replicate the result. Scientists combed over four years of data for events that could be caused by dark matter interacting with electrons in XENON100. The researchers found no evidence of an annual cycle, contradicting DAMA’s claim.
Dark matter optimists can still cling to a caveat, though: DAMA uses a different detection material, composed of sodium iodide crystals rather than xenon. That might explain the difference between the two experiments. Future experiments will attempt to replicate DAMA’s result using the same material.
Dinosaurs might live on today as birds, but they hatched like reptiles. Developing dinos stayed in their eggs three to six months before emerging, far longer than previously suspected, researchers report online January 3 in the Proceedings of the National Academy of Sciences.
With few clues to dinosaurs’ embryonic lives, scientists assumed that young dinosaurs shared modern birds’ swift incubation period, which ranges from 45 to 80 days for eggs in the size range of dino eggs. A reptile egg generally takes about twice as long to hatch as a bird egg of similar size, says lead author Gregory Erickson, a paleobiologist at Florida State University in Tallahassee. But counts of growth lines on the teeth of rare fossilized dinosaur embryos from two species, Protoceratops andrewsi and Hypacrosaurus stebingeri, suggest a longer trajectory like that of reptiles, say Erickson and colleagues at the University of Calgary in Canada and the American Museum of Natural History in New York City. These lines, laid down daily on teeth, can be used like tree rings.
The longer incubation time might have worked against dinosaurs, Erickson says. Guarding a brood of eggs for many months could put parents at risk of attack. And a species hit by environmental catastrophe would have a harder time bouncing back.
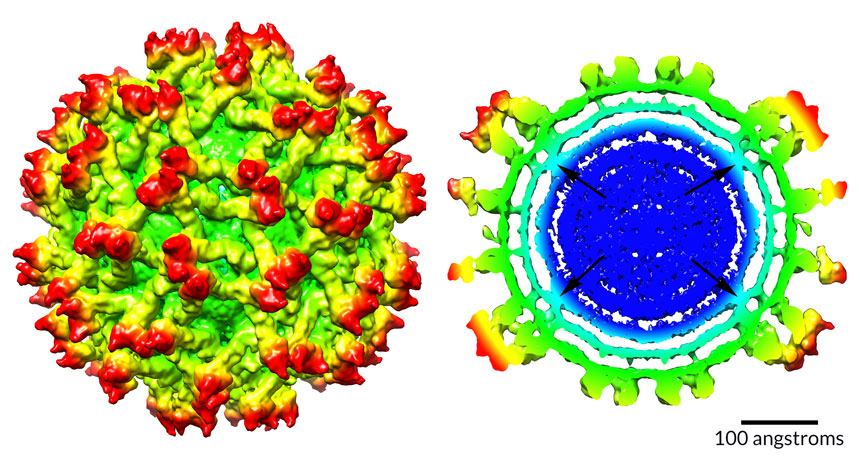
Before an immature Zika virus becomes infectious, it does some major remodeling.
In a fledgling virus particle, the inner protein and RNA core (shown in dark blue above, right) forms bridges to the membrane layer that surrounds it. As the virus matures, the core shuffles around and the bridges melt away (below, right).
It’s the first time scientists have seen such rearrangement in the core of a flavivirus, the group that also includes the viruses that cause dengue, West Nile and yellow fever, says virologist Richard Kuhn of Purdue University in West Lafayette, Ind. Scientists don’t know why the immature Zika virus reshuffles its insides, Kuhn says — perhaps it helps the maturing virus become infectious. But that’s the next big question to answer, he says.
If blocking the reorganization somehow made mature viruses harmless, scientists would have a new clue about preventing Zika infection. Kuhn and colleagues’ map of the immature virus’s structure, published online January 9 in Nature Structural & Molecular Biology, could offer other hints for thwarting Zika.
With a technique called cryo-electron microscopy, the team could see three-headed protein spikes (shown in red) studding the surface like some kind of medieval weapon, and could even distinguish the separate layers of the membrane (aqua) that encloses the core. (The maps are radially colored; colors change as distance from the core increases.) Outside the membrane lie surface proteins called envelope, or E, proteins (green and yellow) that help the virus sneak into cells.
Last year, Kuhn’s team reported the structure of the mature Zika virus (SN: 4/30/16, p. 10). The new work offers another illuminating peek at Zika — a baby picture, of sorts.
Any exercise — even the weekend warrior approach, cramming it all into Saturday and Sunday — is better than none. Compared with inactive adults, those who got the recommended amount of weekly exercise, or even substantially less, had about a one-third lower risk of death during the study period, researchers report online January 9 in JAMA Internal Medicine.
Gary O’Donovan at the University of Leicester in England and colleagues analyzed data from 63,591 people ages 40 and older, surveyed between 1994 and 2012 as part of the Health Survey for England and the Scottish Health Survey. Adults should be getting 150 minutes of moderate activity (such as walking) or 75 minutes of vigorous activity (such as jogging) spread out across the week, according to the U.S. Centers for Disease Control and Prevention and the World Health Organization. Measured against people who did absolutely nothing, active people who worked up a sweat three or more times per week, weekend warriors and even those who moved less (60 minutes per week on average) all reduced their risk of dying early. The observational study can’t say that exercise caused the reduced risk, just that there’s an association.
NASA’s Dawn spacecraft has detected organic compounds on Ceres — the first concrete proof of organics on an object in the asteroid belt between Mars and Jupiter.
This material probably originated on the dwarf planet itself, the researchers report in the Feb. 17 Science. The discovery of organic compounds adds to the growing body of evidence that Ceres may have once had a habitable environment.
“We’ve come to recognize that Ceres has a lot of characteristics that are intriguing for those looking at how life starts,” says Andy Rivkin, a planetary astronomer at the Johns Hopkins University Applied Physics Laboratory in Laurel, Md., who was not involved in the study. The Dawn probe has previously detected salts, ammonia-rich clays and water ice on Ceres, which together indicate hydrothermal activity, says study coauthor Carol Raymond, a planetary scientist at NASA’s Jet Propulsion Laboratory in Pasadena, Calif.
For life to begin, you need elements like carbon, hydrogen, nitrogen and oxygen, as well as a source of energy. Both the hydrothermal activity and the presence of organics point toward Ceres having once had a habitable environment, Raymond says.
“If you have an abundance of those elements and you have an energy source,” she says, “then you’ve created sort of the soup from which life could have formed.” But study coauthor Lucy McFadden, a planetary scientist at NASA’s Goddard Space Flight Center in Greenbelt, Md., stresses that the team has not actually found any signs of life on Ceres.
Evidence of Ceres’ organic material comes from areas near Ernutet crater. Dawn picked up signs of a “fingerprint,” or spectra, consistent with organics. The pattern of wavelengths of light absorbed and reflected from these areas is similar to the pattern seen in hydrocarbons on Earth such as kerite and asphaltite. But without a sample from the surface, the team can’t say definitively what organic material is present or how it formed, says study coauthor Harry McSween, a geologist at the University of Tennessee. The team suspects that the organics formed within Ceres’ interior and were brought to the surface by hydrothermal activity. An alternative idea — that a space rock that crashed into Ceres brought the material — is unlikely, the researchers say, because the concentration of organics is so high. An impact would have mixed organic compounds across the surface, diluting the concentration.
Detecting organics on Ceres also has implications for how life arose on Earth, McSween says. Some researchers think that life was jump-started by asteroids and other space rocks that delivered organic compounds to the planet. Finding such organic matter on Ceres “adds some credence to that idea,” he says.
A person growing up in Peru in the 1970s or 1980s probably didn’t eat anchoveta, the local species of anchovies. The stinky, oily fish was a food fit only for animals or the very poor. The anchoveta fishery may have been (and still is, in many years) the world’s largest, but it wasn’t one that put food on the table.
For thousands of years, though, anchoveta fed the people of Peru. It was only when the industrial fishing fleet got started in the 1950s — one that converted most of its catch into fishmeal for feeding other animals — that people lost interest in the fish.
In fact, of the some 20 million metric tons of fish caught annually around the world for uses other than eating, 90 percent are fish that are perfectly good to eat, such as sardines, anchovies and herring, a new study finds.
“Historically, these fish were eaten for human consumption,” but at some point, like the anchoveta, they gained a reputation as being “trash,” notes Tim Cashion, the study’s lead author.
Cashion is a researcher for the Sea Around Us project at the University of British Columbia’s Institute for the Ocean and Fisheries, and he and his colleagues have been collecting data to illuminate the impact of fisheries on marine ecosystems. Cashion spent a year tallying up fishery catches around the world from 1950 to 2010, figuring out who caught which species and where the fish went after it was taken out of the sea.
About 27 percent of ocean fish caught became fishmeal or fish oil. Those products were used to feed farmed fish or used in agriculture, for purposes such as feeding pigs and chickens. And most of the fish species were either food-grade (used as food somewhere in the world) or prime-food-grade (widely accepted as food everywhere), Cashion and his colleagues report February 13 in Fish and Fisheries.
“There could be a better use of these fish,” says Cashion. Instead of feeding fish to fish, the fish could feed people, especially those who lack access to high-quality sources of protein. But the reason why that doesn’t happen is a combination of economics and regulations. In many places, and for many fish, a fisherman can get more money for his catch if he sells it for fishmeal than if he sells it to the locals for their meals. And in Peru, those economic incentives have combined with a 1992 law and more-recent regulations to keep anchoveta off locals’ plates — despite increased demand brought on by efforts to change the fish’s poor reputation. (These included segments on a popular TV food show.)
By law, the industrial fishing fleet in Peru can only sell anchoveta for fishmeal. Only smaller, artisanal fleets can catch anchoveta for people to eat and can’t legally sell their catch for fishmeal — but the higher price offered by the fishmeal plants means that many do. As a result, the amount of anchoveta that people in Peru consumed dropped by more than half from 2011 to 2014, despite more people actually wanting to eat the fish.
But a change in how the anchoveta are handled could satisfy both the need to feed the Peruvian people and supply the fishmeal industry, Santiago de la Puente of the Institute for the Oceans and Fisheries and colleagues note February 15 in Fish and Fisheries. A ton of anchoveta caught for canning yields 150 kilograms of fish in the can and 600 kilograms of heads, guts and other bits that are perfect for fishmeal. If all the anchoveta were diverted through the canning industry, the researchers calculate a net yearly benefit of 40,000 jobs, $351 million in additional revenue and 40 kilograms of nutrient-rich, tasty fish for every person in Peru.
Big data is everywhere these days and police departments are no exception. As law enforcement agencies are tasked with doing more with less, many are using predictive policing tools. These tools feed various data into algorithms to flag people likely to be involved with future crimes or to predict where crimes will occur.
In the years since Time magazine named predictive policing as one of 2011’s best 50 inventions of the year, its popularity has grown. Twenty U.S. cities, including Chicago, Atlanta, Los Angeles and Seattle are using a predictive policing system, and several more are considering it. But with the uptick in use has come a growing chorus of caution. Community activists, civil rights groups and even some skeptical police chiefs have raised concerns that predictive data approaches may unfairly target some groups of people more than others.
New research by statistician Kristian Lum provides a telling case study. Lum, who leads the policing project at the San Francisco-based Human Rights Data Analysis Group, looked at how the crime-mapping program PredPol would perform if put to use in Oakland, Calif. PredPol, which purports to “eliminate profiling concerns,” takes data on crime type, location and time and feeds it into a machine-learning algorithm. The algorithm, originally based on predicting seismic activity after an earthquake, trains itself with the police crime data and then predicts where future crimes will occur.
Lum was interested in bias in the crime data — not political or racial bias, just the ordinary statistical kind. While this bias knows no color or socioeconomic class, Lum and her HRDAG colleague William Isaac demonstrate that it can lead to policing that unfairly targets minorities and those living in poorer neighborhoods.
By applying the algorithm to 2010 data on drug crime reports for Oakland, the researchers generated a predicted rate of drug crime on a map of the city for every day of 2011. The researchers then compared the data used by the algorithm — drug use documented by the police — with a record of overall drug use, whether recorded or not. This ground-truthing came from taking public health data from the 2011 National Survey on Drug Use and Health and demographic data from the city of Oakland to derive an estimate of drug use for all city residents. In this public health-based map, drug use is widely distributed across the city. In the predicted drug crime map, it is not. Instead, drug use deemed worthy of police attention is concentrated in neighborhoods in West Oakland and along International Boulevard, two predominately low-income and nonwhite areas. Predictive policing approaches are often touted as eliminating concerns about police profiling. But rather than correcting bias, the predictive model exacerbated it, Lum said during a panel on data and crime at the American Association for the Advancement of Science annual meeting in Boston in February. While estimates of drug use are pretty even across race, the algorithm would direct Oakland police to locations that would target black people at roughly twice the rate of whites. A similar disparity emerges when analyzing by income group: Poorer neighborhoods get targeted. And a troubling feedback loop emerges when police are sent to targeted locations. If police find slightly more crime in an area because that’s where they’re concentrating patrols, these crimes become part of the dataset that directs where further patrolling should occur. Bias becomes amplified, hot spots hotter.
There’s nothing wrong with PredPol’s algorithm, Lum notes. Machine learning algorithms learn patterns and structure in data. “The algorithm did exactly what we asked; it learned patterns in the data,” she says. The danger is in thinking that predictive policing will tell you about patterns in the occurrence of crime. It’s really telling you about patterns in police records.
Police aren’t tasked with collecting random samples, nor should they be, says Lum. And that’s all the more reason why departments should be transparent and vigilant about how they use their data. In some ways, PredPol-guided policing isn’t so different from old-fashioned pins on a map.
For her part, Lum would prefer that police stick to these timeworn approaches. With pins on a map, the what, why and where of the data are very clear. The black box of an algorithm, on the other hand, lends undue legitimacy to the police targeting certain locations while simultaneously removing accountability. “There’s a move toward thinking machine learning is our savior,” says Lum. “You hear people say, “A computer can’t be racist.’”
The use of predictive policing may be costly, both literally and figuratively. The software programs can run from $20,000 to up to $100,000 per year for larger cities. It’s harder to put numbers on the human cost of over-policing, but the toll is real. Increased police scrutiny can lead to poor mental health outcomes for residents and undermine relationships between police and the communities they serve. Big data doesn’t help when it’s bad data.
It’s not the size of a snake’s muscles that matter, but how it uses them. King snakes can defeat larger snakes in a wrestling match to the death because of how they coil around their prey, researchers report March 15 in the Journal of Experimental Biology.
King snakes wrap around their food and squeeze with about twice as much pressure as rat snakes do, says David Penning, a functional morphologist at Missouri Southern State University in Joplin. Penning, along with colleague Brad Moon at the University of Louisiana at Lafayette, measured the constriction capabilities of almost 200 snakes. “King snakes are just little brutes,” Penning says. King snakes, which are common in North American forests and grasslands, are constrictor snakes that “wrestle for a living,” Penning says. They mainly eat rodents, birds and eggs, squeezing so hard, they can stop their prey’s heart (SN: 8/22/15, p. 4). In addition, about a quarter of the king snake diet is other snakes. King snakes can easily attack and eat vipers because they’re immune to the venom, but when they take on larger constrictors, such as rat snakes, it has been unclear what gives them the edge. “That’s not how nature goes,” Penning says, because predators are usually larger than their prey.
King snakes, though, can eat snakes up to 35 percent larger than themselves. One of the largest king snake conquests on record, from 1893, is of a 5-foot-3-inch rat snake, about 17 percent larger than the 4-foot-6-inch king snake that consumed it, Penning says. “David Penning is really one of the first researchers that has been looking at the anatomy, physiology and function of these snakes” to understand how king snakes are superior to rat snakes, says Anthony Herrel, a functional morphologist and evolutionary biologist at the French National Museum of Natural History in Paris. To determine what makes these snakes kings, Penning and Moon compared their muscle size, ability to escape attack and the strength of their squeeze to that of rat snakes. In one test, the researchers shook dead rodents enticingly in front of the snakes to goad them into striking and squeezing. Sensors on the rodents recorded the pressure of the squeeze.
The king snakes constricted with an average pressure of about 20 kilopascals, stronger than the pumping pressure of a human heart. Rat snakes in the same tests applied only about 10 kilopascals of pressure.
But the king snakes weren’t bigger body builders. Controlling for body size, the two kinds of snakes “had the exact same quantity of muscle,” Penning says.
The snakes’ more powerful constriction is probably due to how they use their muscles, not how much muscle they have, the researchers conclude. They observed that the majority of king snakes in the study wrapped around their food like a spring in what Penning calls the “curly fry pattern.” Rat snakes didn’t always coil in the same way and often ended up looking like a “weird pile of spaghetti,” he says.
Penning plans to study how other factors influence constriction as well, such as how long the king snakes can squeeze, how hungry they are and the temperature of their environment.
I’ve been to the playground enough times to know a juicy parenting controversy when I see (or overhear) one. Bed-sharing, breastfeeding and screen time are always hot-button issues. But I’m not talking about any of those. No, I’m talking about actual juice.
Some parents see juice as a delicious way to get vitamins into little kids. Others see juice as a gateway drug to a sugar-crusted, sedentary lifestyle, wrapped up in a kid-friendly box. No matter where you fall on the juice spectrum, you can be sure there are parents to either side of you. (Disclosure: My kids don’t drink much juice, simply because the people who buy their groceries aren’t all that into it. And juice is heavy.)
Scientific studies on the effects of juice have been somewhat sparse, allowing deeply held juice opinions to run free. One of the chief charges against juice is that it’s packed with sugar. An 8-ounce serving of grape juice, even with no sugar added, weighs in at 36 grams. That tops Coca-Cola, which delivers 26 grams of sugar in 8 ounces. And all of those extra sweet calories can lead to extra weight.
A recent review of eight studies on juice and children’s body weight, published online March 23 in Pediatrics, takes a look at this weight concern. It attempts to clarify whether kids who drink 100 percent fruit juice every day are at greater risk of gaining weight. After sifting through the studies’ data, researchers arrived at an answer that will please pro-juicers: Not really.
“Our study did not find evidence that consuming one serving per day of 100 percent fruit juice influenced BMI to a clinically important degree,” says study coauthor Brandon Auerbach of the University of Washington in Seattle.
The analysis found that for children ages 1 to 6, one daily serving of juice (6 to 8 ounces) was associated with a sliver of an increase in body mass index, or BMI. Consider a 5-year-old girl who started out right on the 50th percentile for weight and BMI. After a year of daily juice, this girl’s BMI may have moved from the 50th to the 52nd or 54th percentile, corresponding to a weight increase of 0.18 to 0.33 pounds over the year. That amount “isn’t trivial, but it’s not enough on its own to lead to poor health,” Auerbach says.
The results, of course, aren’t the final word. The analysis was reviewing data from other studies, and those studies came with their own limitations. For one thing, the studies didn’t assign children to receive or not receive juice. Instead, researchers measured the children’s juice-drinking behavior that was already under way and tried to relate that to their weight. That approach means that it’s possible that differences other than juice consumption could influence the results. It’s important to note the distinction here between the 100 percent fruit juice in the studies and fruit cocktails, which are fruit-flavored drinks that often come with lots of added sugar. The data on those drinks is more damning in terms of weight gain and the risk of cavities, Auerbach says.
Also worth noting: The American Academy of Pediatrics recommends that kids between ages 1 and 6 get only 4 to 6 ounces of juice a day. That’s a smaller amount than many of the kids in the studies received. And the AAP recommends babies younger than 6 months get no juice at all.
In general, whole fruits, such as apples and oranges, are better than juice because they provide fiber and other nutrients absent from juice. (Bonus for toddlers: Oranges are fun to peel. Bummer for parents: Doing so makes a sticky mess.)
Still, the new analysis may ease some guilt around letting the juice flow. And it can enable parents to save their worries for more harmful things, of which there are plenty.
River piracy RIV-er PAHY-ruh-see n. The diversion of headwaters from one stream into another
Ahoy! There be liquid booty on the move in the high mountains. Since May 2016, a channel carved through one of northwestern Canada’s largest glaciers has allowed one river to pillage water from another, new observations reveal. This phenomenon, almost certainly the result of climate change, is the first modern record of river piracy caused by a melting glacier, researchers report online April 17 in Nature Geoscience. Such piracy was rampant as the colossal ice sheets of the Last Glacial Maximum began shrinking around 18,000 years ago. For hundreds of years, the Kaskawulsh Glacier formed a wall that segregates snow and ice meltwater into two streams: the Slims River, which joins with other streams and crosses Alaska before draining into the Bering Sea, and the Kaskawulsh River, which flows southward into the Pacific Ocean.
Last summer, geomorphologist Daniel Shugar of the University of Washington Tacoma and colleagues discovered that melting had carved a canyon across the toe of Kaskawulsh Glacier. This new channel diverts almost all meltwater into the Kaskawulsh River. That’s robbed the now largely parched Slims River and could decrease fish populations and the availability of nutrients downstream, the researchers predict.