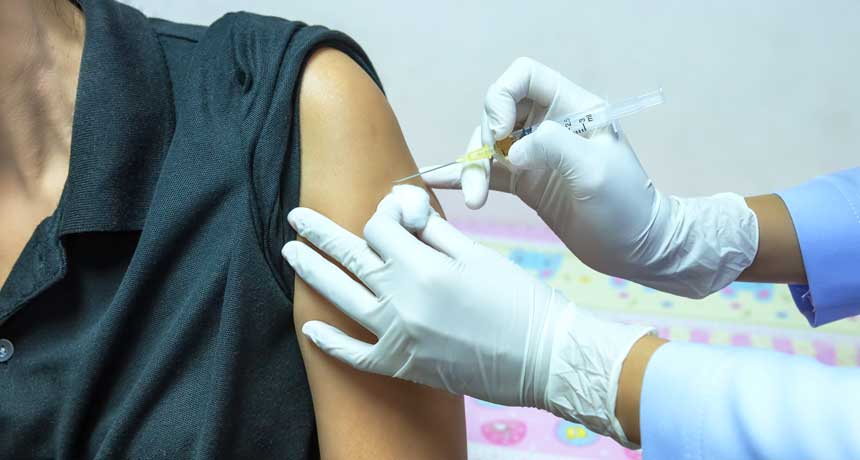
A genetic “crystal ball” can predict whether certain people will respond effectively to the flu vaccine.
Nine genes are associated with a strong immune response to the flu vaccine in those aged 35 and under, a new study finds. If these genes were highly active before vaccination, an individual would generate a high level of antibodies after vaccination, no matter the flu strain in the vaccine, researchers report online August 25 in Science Immunology. This response can help a person avoid getting the flu.
The research team also tried to find a predictive set of genes in people aged 60 and above — a group that includes those more likely to develop serious flu-related complications, such as pneumonia — but failed. Even so, the study is “a step in the right direction,” says Elias Haddad, an immunologist at Drexel University College of Medicine in Philadelphia, who did not participate in the research. “It could have implications in terms of identifying responders versus nonresponders by doing a simple test before a vaccination.”
The U.S. Centers for Disease Control and Prevention estimates that vaccination prevented 5.1 million flu illnesses in the 2015‒2016 season. Getting a flu shot is the best way to stay healthy, but “the problem is, we don’t know what makes a successful vaccination,” says Purvesh Khatri, a computational immunologist at Stanford University School of Medicine. “The immune system is very personal.” Khatri and colleagues wondered if there was a certain immune state one needed to be in to respond effectively to the flu vaccine. So the researchers looked for a common genetic signal in blood samples from 175 people with different genetic backgrounds, from different locations in the United States, and who received the flu vaccine in different seasons. After identifying the set of predictive genes, the team used another collection of 82 samples to confirm that the crystal ball accurately predicted a strong flu response. Using such a variety of samples makes it more likely that the crystal ball will work for many different people in the real world, Khatri says.
The nine genes make proteins that have various jobs, including directing the movement of other proteins and providing structure to cells. Previous research on these genes has tied some of them to the immune system, but not others. Khatri expects the study will spur investigations into how the genes promote a successful vaccine response. And figuring out how to boost the genes may help those who don’t respond strongly to flu vaccine, he says.
As for finding a genetic crystal ball for older adults, “there’s still hope that we’ll be able to,” says team member Raphael Gottardo, a computational biologist at the Fred Hutchinson Cancer Research Center in Seattle. Older people are even more diverse in how they respond to the flu vaccine than younger people, he says, so it may take a larger group of samples to find a common genetic thread.
More research is also needed to learn whether the identified genes will predict an effective response for all vaccines, or just the flu, Haddad says. “There is a long way to go here.”
You’ve probably encountered at least one machine-learning algorithm today. These clever computer codes sort search engine results, weed spam e-mails from inboxes and optimize navigation routes in real time. People entrust these programs with increasingly complex — and sometimes life-changing — decisions, such as diagnosing diseases and predicting criminal activity.
Machine-learning algorithms can make these sophisticated calls because they don’t simply follow a series of programmed instructions the way traditional algorithms do. Instead, these souped-up programs study past examples of how to complete a task, discern patterns from the examples and use that information to make decisions on a case-by-case basis. Unfortunately, letting machines with this artificial intelligence, or AI, figure things out for themselves doesn’t just make them good critical “thinkers,” it also gives them a chance to pick up biases.
Investigations in recent years have uncovered several ways algorithms exhibit discrimination. In 2015, researchers reported that Google’s ad service preferentially displayed postings related to high-paying jobs to men. A 2016 ProPublica investigation found that COMPAS, a tool used by many courtrooms to predict whether a criminal will break the law again, wrongly predicted that black defendants would reoffend nearly twice as often as it made that wrong prediction for whites. The Human Rights Data Analysis Group also showed that the crime prediction tool PredPol could lead police to unfairly target low-income, minority neighborhoods (SN Online: 3/8/17). Clearly, algorithms’ seemingly humanlike intelligence can come with humanlike prejudices.
“This is a very common issue with machine learning,” says computer scientist Moritz Hardt of the University of California, Berkeley. Even if a programmer designs an algorithm without prejudicial intent, “you’re very likely to end up in a situation that will have fairness issues,” Hardt says. “This is more the default than the exception.” Developers may not even realize a program has taught itself certain prejudices. This problem gets down to what is known as a black box issue: How exactly is an algorithm reaching its conclusions? Since no one tells a machine-learning algorithm exactly how to do its job, it’s often unclear — even to the algorithm’s creator — how or why it ends up using data the way it does to make decisions. Several socially conscious computer and data scientists have recently started wrestling with the problem of machine bias. Some have come up with ways to add fairness requirements into machine-learning systems. Others have found ways to illuminate the sources of algorithms’ biased behavior. But the very nature of machine-learning algorithms as self-taught systems means there’s no easy fix to make them play fair.
Learning by example In most cases, machine learning is a game of algorithm see, algorithm do. The programmer assigns an algorithm a goal — say, predicting whether people will default on loans. But the machine gets no explicit instructions on how to achieve that goal. Instead, the programmer gives the algorithm a dataset to learn from, such as a cache of past loan applications labeled with whether the applicant defaulted.
The algorithm then tests various ways to combine loan application attributes to predict who will default. The program works through all of the applications in the dataset, fine-tuning its decision-making procedure along the way. Once fully trained, the algorithm should ideally be able to take any new loan application and accurately determine whether that person will default.
The trouble arises when training data are riddled with biases that an algorithm may incorporate into its decisions. For instance, if a human resources department’s hiring algorithm is trained on historical employment data from a time when men were favored over women, it may recommend hiring men more often than women. Or, if there were fewer female applicants in the past, then the algorithm has fewer examples of those applications to learn from, and it may not be as accurate at judging women’s applications. At first glance, the answer seems obvious: Remove any sensitive features, such as race or sex, from the training data. The problem is, there are many ostensibly nonsensitive aspects of a dataset that could play proxy for some sensitive feature. Zip code may be strongly related to race, college major to sex, health to socioeconomic status.
And it may be impossible to tell how different pieces of data — sensitive or otherwise — factor into an algorithm’s verdicts. Many machine-learning algorithms develop deliberative processes that involve so many thousands of complex steps that they’re impossible for people to review.
Creators of machine-learning systems “used to be able to look at the source code of our programs and understand how they work, but that era is long gone,” says Simon DeDeo, a cognitive scientist at Carnegie Mellon University in Pittsburgh. In many cases, neither an algorithm’s authors nor its users care how it works, as long as it works, he adds. “It’s like, ‘I don’t care how you made the food; it tastes good.’ ”
But in other cases, the inner workings of an algorithm could make the difference between someone getting parole, an executive position, a mortgage or even a scholarship. So computer and data scientists are coming up with creative ways to work around the black box status of machine-learning algorithms.
Setting algorithms straight Some researchers have suggested that training data could be edited before given to machine-learning programs so that the data are less likely to imbue algorithms with bias. In 2015, one group proposed testing data for potential bias by building a computer program that uses people’s nonsensitive features to predict their sensitive ones, like race or sex. If the program could do this with reasonable accuracy, the dataset’s sensitive and nonsensitive attributes were tightly connected, the researchers concluded. That tight connection was liable to train discriminatory machine-learning algorithms.
To fix bias-prone datasets, the scientists proposed altering the values of whatever nonsensitive elements their computer program had used to predict sensitive features. For instance, if their program had relied heavily on zip code to predict race, the researchers could assign fake values to more and more digits of people’s zip codes until they were no longer a useful predictor for race. The data could be used to train an algorithm clear of that bias — though there might be a tradeoff with accuracy.
On the flip side, other research groups have proposed de-biasing the outputs of already-trained machine-learning algorithms. In 2016 at the Conference on Neural Information Processing Systems in Barcelona, Hardt and colleagues recommended comparing a machine-learning algorithm’s past predictions with real-world outcomes to see if the algorithm was making mistakes equally for different demographics. This was meant to prevent situations like the one created by COMPAS, which made wrong predictions about black and white defendants at different rates. Among defendants who didn’t go on to commit more crimes, blacks were flagged by COMPAS as future criminals more often than whites. Among those who did break the law again, whites were more often mislabeled as low-risk for future criminal activity.
For a machine-learning algorithm that exhibits this kind of discrimination, Hardt’s team suggested switching some of the program’s past decisions until each demographic gets erroneous outputs at the same rate. Then, that amount of output muddling, a sort of correction, could be applied to future verdicts to ensure continued even-handedness. One limitation, Hardt points out, is that it may take a while to collect a sufficient stockpile of actual outcomes to compare with the algorithm’s predictions. A third camp of researchers has written fairness guidelines into the machine-learning algorithms themselves. The idea is that when people let an algorithm loose on a training dataset, they don’t just give the software the goal of making accurate decisions. The programmers also tell the algorithm that its outputs must meet some certain standard of fairness, so it should design its decision-making procedure accordingly.
In April, computer scientist Bilal Zafar of the Max Planck Institute for Software Systems in Kaiserslautern, Germany, and colleagues proposed that developers add instructions to machine-learning algorithms to ensure they dole out errors to different demographics at equal rates — the same type of requirement Hardt’s team set. This technique, presented in Perth, Australia, at the International World Wide Web Conference, requires that the training data have information about whether the examples in the dataset were actually good or bad decisions. For something like stop-and-frisk data, where it’s known whether a frisked person actually had a weapon, the approach works. Developers could add code to their program that tells it to account for past wrongful stops.
Zafar and colleagues tested their technique by designing a crime-predicting machine-learning algorithm with specific nondiscrimination instructions. The researchers trained their algorithm on a dataset containing criminal profiles and whether those people actually reoffended. By forcing their algorithm to be a more equal opportunity error-maker, the researchers were able to reduce the difference between how often blacks and whites who didn’t recommit were wrongly classified as being likely to do so: The fraction of people that COMPAS mislabeled as future criminals was about 45 percent for blacks and 23 percent for whites. In the researchers’ new algorithm, misclassification of blacks dropped to 26 percent and held at 23 percent for whites.
These are just a few recent additions to a small, but expanding, toolbox of techniques for forcing fairness on machine-learning systems. But how these algorithmic fix-its stack up against one another is an open question since many of them use different standards of fairness. Some require algorithms to give members of different populations certain results at about the same rate. Others tell an algorithm to accurately classify or misclassify different groups at the same rate. Still others work with definitions of individual fairness that require algorithms to treat people who are similar barring one sensitive feature similarly. To complicate matters, recent research has shown that, in some cases, meeting more than one fairness criterion at once can be impossible.
“We have to think about forms of unfairness that we may want to eliminate, rather than hoping for a system that is absolutely fair in every possible dimension,” says Anupam Datta, a computer scientist at Carnegie Mellon.
Still, those who don’t want to commit to one standard of fairness can perform de-biasing procedures after the fact to see whether outputs change, Hardt says, which could be a warning sign of algorithmic bias.
Show your work But even if someone discovered that an algorithm fell short of some fairness standard, that wouldn’t necessarily mean the program needed to be changed, Datta says. He imagines a scenario in which a credit-classifying algorithm might give favorable results to some races more than others. If the algorithm based its decisions on race or some race-related variable like zip code that shouldn’t affect credit scoring, that would be a problem. But what if the algorithm’s scores relied heavily on debt-to-income ratio, which may also be associated with race? “We may want to allow that,” Datta says, since debt-to-income ratio is a feature directly relevant to credit.
Of course, users can’t easily judge an algorithm’s fairness on these finer points when its reasoning is a total black box. So computer scientists have to find indirect ways to discern what machine-learning systems are up to.
One technique for interrogating algorithms, proposed by Datta and colleagues in 2016 in San Jose, Calif., at the IEEE Symposium on Security and Privacy, involves altering the inputs of an algorithm and observing how that affects the outputs. “Let’s say I’m interested in understanding the influence of my age on this decision, or my gender on this decision,” Datta says. “Then I might be interested in asking, ‘What if I had a clone that was identical to me, but the gender was flipped? Would the outcome be different or not?’ ” In this way, the researchers could determine how much individual features or groups of features affect an algorithm’s judgments. Users performing this kind of auditing could decide for themselves whether the algorithm’s use of data was cause for concern. Of course, if the code’s behavior is deemed unacceptable, there’s still the question of what to do about it. There’s no “So your algorithm is biased, now what?” instruction manual. The effort to curb machine bias is still in its nascent stages. “I’m not aware of any system either identifying or resolving discrimination that’s actively deployed in any application,” says Nathan Srebro, a computer scientist at the University of Chicago. “Right now, it’s mostly trying to figure things out.”
Computer scientist Suresh Venkatasubramanian agrees. “Every research area has to go through this exploration phase,” he says, “where we may have only very preliminary and half-baked answers, but the questions are interesting.”
Still, Venkatasubramanian, of the University of Utah in Salt Lake City, is optimistic about the future of this important corner of computer and data science. “For a couple of years now … the cadence of the debate has gone something like this: ‘Algorithms are awesome, we should use them everywhere. Oh no, algorithms are not awesome, here are their problems,’ ” he says. But now, at least, people have started proposing solutions, and weighing the various benefits and limitations of those ideas. So, he says, “we’re not freaking out as much.”
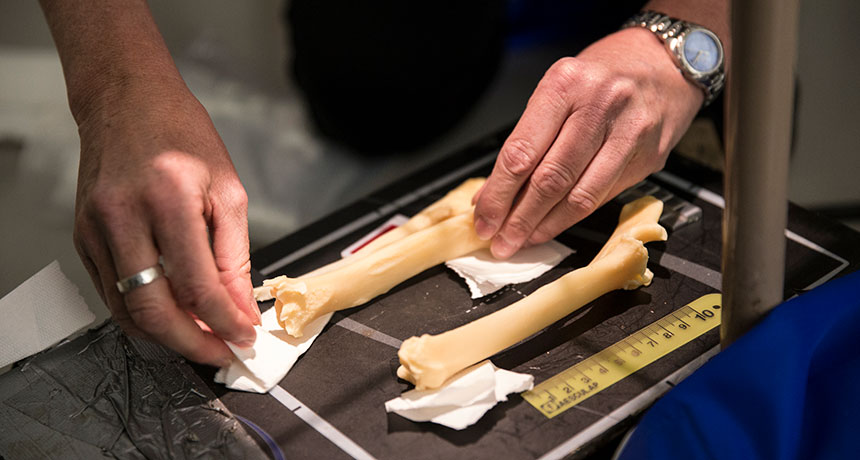
In the scientific version of her obituary, Dolly the Sheep was reported to have suffered from severe arthritis in her knees. The finding and Dolly’s early death from an infection led many researchers to think that cloning might cause animals to age prematurely.
But new X-rays of Dolly’s skeleton and those of other cloned sheep and Dolly’s naturally conceived daughter Bonnie indicate that the world’s first cloned mammal had the joints of normal sheep of her age. Just like other sheep, Dolly had a little bit of arthritis in her hips, knees and elbows, developmental biologist Kevin Sinclair of the University of Nottingham in England and colleagues report November 23 in Scientific Reports. The researchers decided to reexamine Dolly’s remains after finding that her cloned “sisters” have aged normally and didn’t have massive arthritis (SN: 8/20/16, p. 6). No formal records of Dolly’s original arthritis exams were kept, so Sinclair and colleagues got Dolly’s and Bonnie’s skeletons and those of two other cloned sheep, Megan and Morag, from the National Museums Scotland in Edinburgh. Megan and Bonnie were both older than Dolly at the time of their deaths and had more bone damage than Dolly did. Morag died younger and had less damage. Dolly’s arthritis levels were similar to those of naturally conceived sheep her age, indicating that cloning wasn’t to blame. “If there were a direct link with cloning and osteoarthritis, we would have expected to find a lot worse, and it would be more extensive and have a different distribution than what we’re finding in ordinary sheep,” says study coauthor Sandra Corr, a veterinary orthopedic specialist at the University of Glasgow in Scotland. Dolly’s slightly creaky joints may have stemmed from giving birth to six lambs, including Bonnie. Pregnancy is a risk factor for arthritis in sheep.
NEW ORLEANS — Saturn’s mighty rings cast a long shadow on the gas giant — and not just in visible light.
Final observations from the Cassini spacecraft show that the rings block the sunlight that charges particles in Saturn’s atmosphere. The rings may even be raining charged water particles onto the planet, researchers report online December 11 in Science and at the fall meeting of the American Geophysical Union.
In the months before plunging into Saturn’s atmosphere in September (SN Online: 9/15/17), the Cassini spacecraft made a series of dives between the gas giant and its iconic rings (SN Online: 4/21/17). Some of those orbits took the spacecraft directly into Saturn’s ionosphere, a layer of charged particles in the upper atmosphere. The charged particles are mostly the result of ultraviolet radiation from the sun separating electrons from atoms. Jan-Erik Wahlund of the Swedish Institute of Space Physics in Uppsala and Ann Persoon of the University of Iowa in Iowa City and their colleagues examined data from 11 of Cassini’s dives through the rings. The researchers found a lower density of charged particles in the regions associated with the ring shadows than elsewhere in the ionosphere. That finding suggests the rings block ultraviolet light, the team concludes.
Blocked sunlight can’t explain everything surprising about the ionosphere, though. The ionosphere was more variable than the researchers expected, with its electron density sometimes changing by more than an order of magnitude from one Cassini orbit to the next.
Charged water particles chipped off of the rings could periodically splash into the ionosphere and sop up the free electrons, the researchers suggest. This idea, known as “ring rain,” was proposed in the 1980s (SN: 8/9/86, p. 84) but has still never been observed directly.
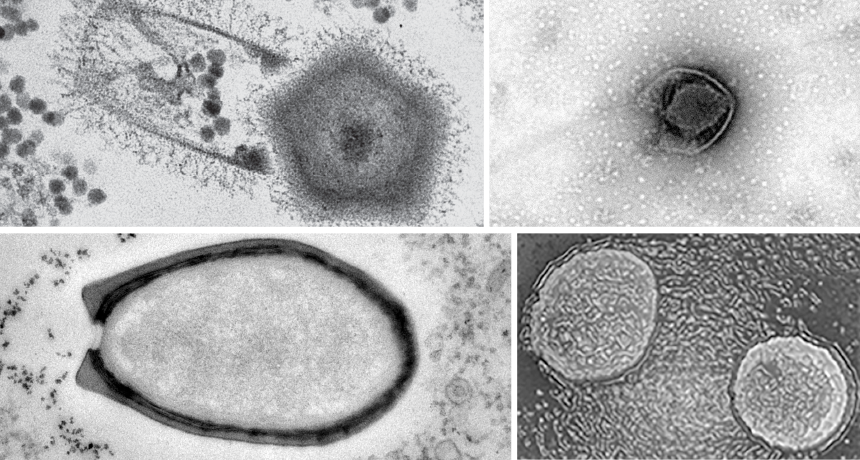
For decades, the name “virus” meant small and simple. Not anymore. Meet the giants.
Today, scientists are finding ever bigger viruses that pack impressive amounts of genetic material. The era of the giant virus began in 2003 with the discovery of the first Mimivirus (SN: 5/23/09, p. 9). The viral titan is about 750 nanometers across with a genetic pantry boasting around 1.2 million base pairs of DNA, the information-toting bits often represented with A, T, C and G. Influenza A, for example, is roughly 100 nanometers across with only about 13,500 base pairs of genetic material.
In 2009, another giant virus called Marseillevirus was identified. It is different enough from mimiviruses to earn its own family. Since 2013, mega-sized viruses falling into another eight potential virus families have been found, showcasing a long-unexplored viral diversity, researchers reported last year in Annual Review of Virology and in January in Frontiers in Microbiology.
Giant viruses mostly come in two shapes: polyhedral capsules and egglike ovals. But one, Mollivirus, skews more spherical. Pacmanvirus was named for the broken appearance of its outer shell. Both represent potential families. Two newly discovered members of the mimivirus family, both called tupanviruses and both with tails, have the most complete set of genes related to assembling proteins yet seen in viruses (SN Online: 2/27/18). Once unheard of, giant viruses may be common in water and soils worldwide. Only time — and more discoveries — will tell. Virus length and genome size for a representative from each of two recognized giant virus families (mimivirus and marseillevirus families) and eight potential families are shown. Circles are scaled to genome size and shaded by size range, with influenza A and E. coli bacterium included for comparison. Years indicate when the first viruses were described.
Graphic: C. Chang; Sources: P. Colson, B. La Scola and D. Raoult/Annual Review of Virology 2017; J. Andreani et al/Frontiers in Microbiology 2018
When you’re stressed and anxious, you might feel your heart race. Is your heart racing because you’re afraid? Or does your speeding heart itself contribute to your anxiety? Both could be true, a new study in mice suggests.
By artificially increasing the heart rates of mice, scientists were able to increase anxiety-like behaviors — ones that the team then calmed by turning off a particular part of the brain. The study, published in the March 9 Nature, shows that in high-risk contexts, a racing heart could go to your head and increase anxiety. The findings could offer a new angle for studying and, potentially, treating anxiety disorders. The idea that body sensations might contribute to emotions in the brain goes back at least to one of the founders of psychology, William James, says Karl Deisseroth, a neuroscientist at Stanford University. In James’ 1890 book The Principles of Psychology, he put forward the idea that emotion follows what the body experiences. “We feel sorry because we cry, angry because we strike, afraid because we tremble,” James wrote.
The brain certainly can sense internal body signals, a phenomenon called interoception. But whether those sensations — like a racing heart — can contribute to emotion is difficult to prove, says Anna Beyeler, a neuroscientist at the French National Institute of Health and Medical Research in Bordeaux. She studies brain circuitry related to emotion and wrote a commentary on the new study but was not involved in the research. “I’m sure a lot of people have thought of doing these experiments, but no one really had the tools,” she says.
Deisseroth has spent his career developing those tools. He is one of the scientists who developed optogenetics — a technique that uses viruses to modify the genes of specific cells to respond to bursts of light (SN: 6/18/21; SN: 1/15/10). Scientists can use the flip of a light switch to activate or suppress the activity of those cells. In the new study, Deisseroth and his colleagues used a light attached to a tiny vest over a mouse’s genetically engineered heart to change the animal’s heart rate. When the light was off, a mouse’s heart pumped at about 600 beats per minute. But when the team turned on a light that flashed at 900 beats per minutes, the mouse’s heartbeat followed suit. “It’s a nice reasonable acceleration, [one a mouse] would encounter in a time of stress or fear,” Deisseroth explains.
When the mice felt their hearts racing, they showed anxiety-like behavior. In risky scenarios — like open areas where a little mouse might be someone’s lunch — the rodents slunk along the walls and lurked in darker corners. When pressing a lever for water that could sometimes be coupled with a mild shock, mice with normal heart rates still pressed without hesitation. But mice with racing hearts decided they’d rather go thirsty.
“Everybody was expecting that, but it’s the first time that it has been clearly demonstrated,” Beyeler says. The researchers also scanned the animals’ brains to find areas that might be processing the increased heart rate. One of the biggest signals, Deisseroth says, came from the posterior insula (SN: 4/25/16). “The insula was interesting because it’s highly connected with interoceptive circuitry,” he explains. “When we saw that signal, [our] interest was definitely piqued.”
Using more optogenetics, the team reduced activity in the posterior insula, which decreased the mice’s anxiety-like behaviors. The animals’ hearts still raced, but they behaved more normally, spending some time in open areas of mazes and pressing levers for water without fear. A lot of people are very excited about the work, says Wen Chen, the branch chief of basic medicine research for complementary and integrative health at the National Center for Complementary and Integrative Health in Bethesda, Md. “No matter what kind of meetings I go into, in the last two days, everybody brought up this paper,” says Chen, who wasn’t involved in the research.
The next step, Deisseroth says, is to look at other parts of the body that might affect anxiety. “We can feel it in our gut sometimes, or we can feel it in our neck or shoulders,” he says. Using optogenetics to tense a mouse’s muscles, or give them tummy butterflies, might reveal other pathways that produce fearful or anxiety-like behaviors.
Understanding the link between heart and head could eventually factor into how doctors treat panic and anxiety, Beyeler says. But the path between the lab and the clinic, she notes, is much more convoluted than that of the heart to the head.
An experimental treatment for endometriosis, a painful gynecological disease that affects some 190 million people worldwide, may one day offer new hope for easing symptoms.
Monthly antibody injections reversed telltale signs of endometriosis in monkeys, researchers report February 22 in Science Translational Medicine. The antibody targets IL-8, a molecule that whips up inflammation inside the scattered, sometimes bleeding lesions that mark the disease. After neutralizing IL-8, those hallmark lesions shrink, the team found.
The new treatment is “pretty potent,” says Philippa Saunders, a reproductive scientist at the University of Edinburgh who was not involved with work. The study’s authors haven’t reported a cure, she points out, but their antibody does seem to have an impact. “I think it’s really very promising,” she says.
Many scientists think endometriosis occurs when bits of the uterine lining — the endometrium — slough off during menstruation. Instead of exiting via the vagina, they voyage in the other direction: up through the fallopian tubes. Those bits of tissue then trespass through the body, sprouting lesions where they land. They’ll glom onto the ovaries, fallopian tubes, bladder and other spots outside of the uterus and take on a life of their own, Saunders says. The lesions can grow nerve cells, form tough nubs of tissue and even bleed during menstrual cycles. They can also kick off chronic bouts of pelvic pain. If you have endometriosis, you can experience “pain when you urinate, pain when you defecate, pain when you have sex, pain when you move around,” Saunders says. People with the disease can also struggle with infertility and depression, she adds. “It’s really nasty.” Once diagnosed, patients face a dearth of treatment options — there’s no cure, only therapies to alleviate symptoms. Surgery to remove lesions can help, but symptoms often come back.
The disease affects at least 10 percent of girls, women and transgender men in their reproductive years, Saunders says. And people typically suffer for years — about eight on average — before a diagnosis. “Doctors consider menstrual pelvic pain a very common thing,” says Ayako Nishimoto-Kakiuchi, a pharmacologist at Chugai Pharmaceutical Co. Ltd. in Tokyo. Endometriosis “is underestimated in the clinic,” she says. “I strongly believe that this disease has been understudied.”
Hormonal drugs that stop ovulation and menstruation can also offer relief, says Serdar Bulun, a reproductive endocrinologist at Northwestern University Feinberg School of Medicine in Chicago not involved with the new study. But those drugs come with side effects and aren’t ideal for people trying to become pregnant. “I see these patients day in and day out,” he says. “I see how much they suffer, and I feel like we are not doing enough.”
Nishimoto-Kakiuchi’s team engineered an antibody that grabs onto the inflammatory factor IL-8, a protein that scientists have previously fingered as one potential culprit in the disease. The antibody acts like a garbage collector, Nishimoto-Kakiuchi says. It grabs IL-8, delivers it to the cell’s waste disposal machinery, and then heads out to snare more IL-8.
The team tested the antibody in cynomolgus monkeys that were surgically modified to have the disease. (Endometriosis rarely shows up spontaneously in these monkeys, the scientists discovered previously after screening more than 600 females.) The team treated 11 monkeys with the antibody injection once a month for six months. In these animals, lesions shriveled and the adhesive tissue that glues them to the body thinned out, too. Before this study, Nishimoto-Kakiuchi says, the team didn’t think such signs of endometriosis were reversible. Her company has now started a Phase I clinical trial to test the safety of therapy in humans. The treatment is one of several endometriosis therapies scientists are testing (SN: 7/19/19) . Other trials will test new hormonal drugs, robot-assisted surgery and behavioral interventions.
Doctors need new options to help people with the disease, Saunders says. “There’s a huge unmet clinical need.”
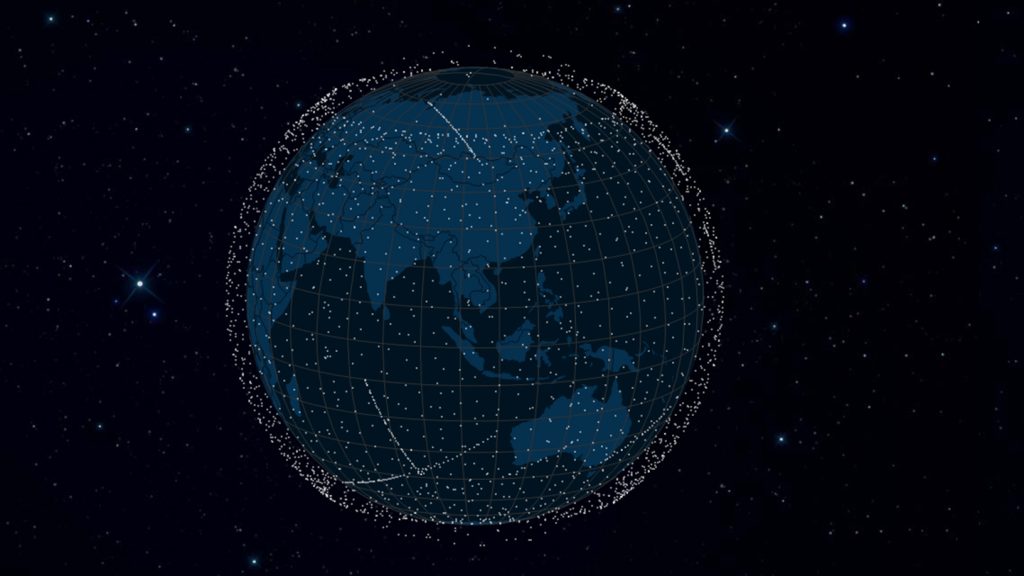
SpaceX’s rapidly growing fleet of Starlink internet satellites now make up half of all active satellites in Earth orbit.
On February 27, the aerospace company launched 21 new satellites to join its broadband internet Starlink fleet. That brought the total number of active Starlink satellites to 3,660, or about 50 percent of the nearly 7,300 active satellites in orbit, according to analysis by astronomer Jonathan McDowell using data from SpaceX and the U.S. Space Force. “These big low-orbit internet constellations have come from nowhere in 2019, to dominating the space environment in 2023,” says McDowell, of the Harvard-Smithsonian Center for Astrophysics in Cambridge, Mass. “It really is a massive shift and a massive industrialization of low orbit.”
SpaceX has been launching Starlink satellites since 2019 with the goal of bringing broadband internet to remote parts of the globe. And for just as long, astronomers have been warning that the bright satellites could mess up their view of the cosmos by leaving streaks on telescope images as they glide past (SN: 3/12/20).
Even the Hubble Space Telescope, which orbits more than 500 kilometers above the Earth’s surface, is vulnerable to these satellite streaks, as well as those from other satellite constellations. From 2002 to 2021, the percentage of Hubble images affected by light from low-orbit satellites increased by about 50 percent, astronomer Sandor Kruk of the Max-Planck Institute for Extraterrestrial Physics in Garching, Germany, and colleagues report March 2 in Nature Astronomy.
The number of images partially blocked by satellites is still small, the team found, rising from nearly 3 percent of images taken between 2002 and 2005 to just over 4 percent between 2018 and 2021 for one of Hubble’s cameras. But there are already thousands more Starlink satellites now than there were in 2021.
“The fraction of [Hubble] images crossed by satellites is currently small with a negligible impact on science,” Kruk and colleagues write. “However, the number of satellites and space debris will only increase in the future.” The team predicts that by the 2030s, the probability of a satellite crossing Hubble’s field of view any time it takes an image will be between 20 and 50 percent. The sudden jump in Starlink satellites also poses a problem for space traffic, says astronomer Samantha Lawler of the University of Regina in Canada. Starlink satellites all orbit at a similar distance from Earth, just above 500 kilometers.
“Starlink is the densest patch of space that has ever existed,” Lawler says. The satellites are constantly navigating out of each other’s way to avoid collisions (SN: 2/12/09). And it’s a popular orbital altitude — Hubble is there, and so is the International Space Station and the Chinese space station. “If there is some kind of collision [between Starlinks], some kind of mishap, it could immediately affect human lives,” Lawler says.
SpaceX launches Starlink satellites roughly once per week — it launched 51 more on March 3. And they’re not the only company launching constellations of internet satellites. By the 2030s, there could be 100,000 satellites crowding low Earth orbit.
So far, there are no international regulations to curb the number of satellites a private company can launch or to limit which orbits they can occupy.
“The speed of commercial development is much faster than the speed of regulation change,” McDowell says. “There needs to be an overhaul of space traffic management and space regulation generally to cope with these massive commercial projects.”
The oldest known fossils of pollen-laden insects are of earwig-like ground-dwellers that lived in what is now Russia about 280 million years ago, researchers report. Their finding pushes back the fossil record of insects transporting pollen from one plant to another, a key aspect of modern-day pollination, by about 120 million years.
The insects — from a pollen-eating genus named Tillyardembia first described in 1937 — were typically about 1.5 centimeters long, says Alexander Khramov, a paleoentomologist at the Borissiak Paleontological Institute in Moscow. Flimsy wings probably kept the creatures mostly on the forest floor, he says, leaving them to climb trees to find and consume their pollen.
Recently, Khramov and his colleagues scrutinized 425 fossils of Tillyardembia in the institute’s collection. Six had clumps of pollen grains trapped on their heads, legs, thoraxes or abdomens, the team reports February 28 in Biology Letters. A proportion that small isn’t surprising, Khramov says, because the fossils were preserved in what started out as fine-grained sediments. The early stages of fossilization in such material would tend to wash away pollen from the insects’ remains. The pollen-laden insects had only a couple of types of pollen trapped on them, the team found, suggesting that the critters were very selective in the tree species they visited. “That sort of specialization is in line with potential pollinators,” says Michael Engel, a paleoentomologist at the University of Kansas in Lawrence who was not involved in the study. “There’s probably vast amounts of such specialization that occurred even before Tillyardembia, we just don’t have evidence of it yet.”
Further study of these fossils might reveal if Tillyardembia had evolved special pollen-trapping hairs or other such structures on their bodies or heads, says Conrad Labandeira, a paleoecologist at the National Museum of Natural History in Washington, D.C., also not part of the study. It would also be interesting, he says, to see if something about the pollen helped it stick to the insects. If the pollen grains had structures that enabled them to clump more readily, for example, then those same features may have helped them grab Velcro-like onto any hairlike structures on the insects’ bodies.
Fungi may help some tree-killer beetles turn a tree’s natural defense system against itself.
The Eurasian spruce bark beetle (Ips typographus) has massacred millions of conifers in forests across Europe. Now, research suggests that fungi associated with these bark beetles are key players in the insect’s hostile takeovers. These fungi warp the chemical defenses of host trees to create an aroma that attracts beetles to burrow, researchers report February 21 in PLOS Biology.
This fungi-made perfume might explain why bark beetles tend to swarm the same tree. As climate change makes Europe’s forests more vulnerable to insect invasions, understanding this relationship could help scientists develop new countermeasures to ward off beetle attacks. Bark beetles are a type of insect found around the world that feed and breed inside trees (SN: 12/17/10). In recent years, several bark beetle species have aggressively attacked forests from North America to Australia, leaving ominous strands of dead trees in their wake.
But trees aren’t defenseless. Conifers — which include pine and fir trees — are veritable chemical weapons factories. The evergreen smell of Christmas trees and alpine forests comes from airborne varieties of these chemicals. But while they may smell delightful, these chemicals’ main purpose is to trap and poison invaders.
Or at least, that’s what they’re meant to do.
“Conifers are full of resin and other stuff that should do horrible things to insects,” says Jonathan Gershenzon, a chemical ecologist at the Max Planck Institute for Chemical Ecology in Jena, Germany. “But bark beetles don’t seem to mind at all.”
This ability of bark beetles to overcome the powerful defense system of conifers has led some scientists to wonder if fungi might be helping. Fungi break down compounds in their environment for food and protection (SN: 11/30/21). And some type of fungi — including some species in the genus Grosmannia — are always found in association with Eurasian spruce bark beetles. Gershenzon and his colleagues compared the chemicals released by spruce bark infested with Grosmannia and other fungi to the chemical profile of uninfected trees. The presence of the fungi fundamentally changed the chemical profile of spruce trees, the team found. More than half the airborne chemicals — made by fungi breaking down monoterpenes and other chemicals that are likely part of the tree defense system — were unique to infected trees after 12 days.
This is surprising because researchers had previously assumed that invading fungi hardly changed the chemical profile of trees, says Jonathan Cale, a fungal ecologist at the University of Northern British Columbia in Prince George, Canada, who was not involved with the research. Later experiments revealed that bark beetles can detect many of these fungi-made chemicals. The team tested this by attaching tiny electrodes on bark beetles’ heads and detecting electrical activity when the chemicals wafted passed their antennae. What’s more, the smell of these chemicals combined with beetle pheromones led the insects to burrow at higher rates than the smell of pheromones alone.
The study suggests that these fungi-made chemicals can help beetles tell where to feed and breed, possibly by advertising that the fungi has taken down some of the tree’s defenses. The attractive nature of the chemicals could also explain the beetle’s swarming behavior, which drives the death of healthy adult trees.
But while the fungi aroma might doom trees, it could also lead to the beetles’ demise. Beetle traps in Europe currently use only beetle pheromones to attract their victims. Combining pheromones with fungi-derived chemicals might be the secret to entice more beetles into traps, making them more effective.
The results present “an exciting direction for developing new tools to manage destructive bark beetle outbreaks” for other beetle species as well, Cale says. In North America, mild winters and drought have put conifer forests at greater risk from mountain pine beetle (Dendroctonus pendersoae) attacks. Finding and using fungi-derived chemicals might be one way to fend off the worst of the bark beetle invasions in years to come.